ドロップアウトのイメージ

ドロップアウトとは、過学習を抑制する手段としてランダムにニューロンを消去しながら学習する手法です。
ニューラルネットワークのモデルが複雑になってくると用いられるとのことです。
イメージとしては以下のようになります。

ドロップアウトのサンプルプログラム
0からDeep Learningのソースコードまんまです。
クラスとして提供していただいております。
以下のコードを参照ください。
0.5の乗算することでモデルの平均値にしています。
実際に使う場合は、多層ニューラルネットワークの構築が必要でサンプルプログラムとしても煩雑になりますので割愛しますね。
(またの機会に説明できるように頑張ります)
import numpy as np
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
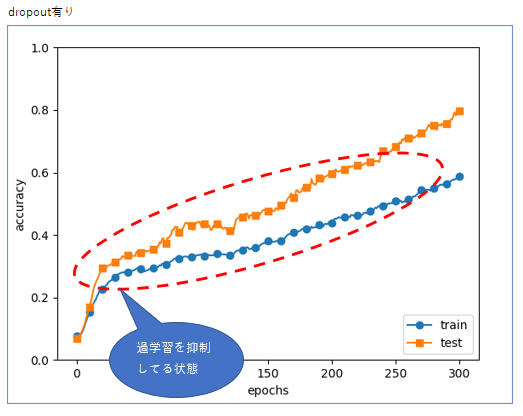
return dout * self.maskドロップアウトを利用した場合のグラフ
最後にグラフがどのように表示されるのかをご紹介します。
ドロップアウトを使わなかったものが上のグラフ。
ドロップアウトを使ったものが下のグラフになります。
上のグラフは学習データの3分の1を取り込んだあたりから100%の認識精度に到達してしまい、残りの学習データが意味のないデータ(過学習状態)になっていますが、下のグラフは学習データを無駄なくしっかり学習しているため、認識精度が上がっていることがわかります。
(多くの学習データを取り込んでいる分だけ学習精度が高くなる)
詳しい説明は、斎藤康毅 著 「セロから作るDeep Learning」をご参照ください。

引用元
オライリーJapan 斎藤康毅 著 「セロから作るDeep Learning」