重みパラメータの最適化

ニューラルネットワークの学習の目的は、損失関数の値をできるだけ小さくするパラメータを見つけることです。
その重みパラメータを最適化する手法としてSGD(Stochastic Gradient D
escentの略)という手法があります。
SGDは以下の数式で書くことができます。更新する重みパラメータはWになります。SGDは勾配方向へある一定の距離だけ進む特徴があります。
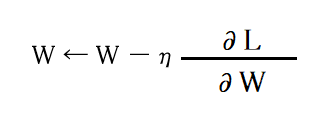
SGDのサンプルプログラム
SGDは以下のような実装になります。
ソースはお馴染みの「0からDeep Learning」からの抜粋です。
初期化関数の引数「lr」は学習係数(Learning Rate)を表します。
プログラムの詳細な説明は「0からDeep Learning」を参照してください。
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, prams, grads):
for key in prams.keys():
prams[key] -= self.lr * grads[key]SGDのグラフ
CGDがどのように最適化されたパラメータを作っていくか
グラフにすると、とてもよくわかります。
以下のプログラムを実行してみてください。
その下のグラフが表示されると思います。
最小値(0,0)へジグザグしながら最適化していることがわかります。
import sys, os
sys.path.append(os.pardir)
import matplotlib.pyplot as plt
from collections import OrderedDict
from common.optimizer import *
def f(x, y):
return x ** 2 / 20.0 + y ** 2
def df(x, y):
return x / 10.0, 2.0 * y
init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=0.95)
idx = 1
for key in optimizers:
optimizer = optimizers[key]
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(10000):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
plt.subplot(1, 1, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="red")
plt.contour(X, Y, Z)
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
# colorbar()
# spring()
plt.title(key)
plt.xlabel("x")
plt.ylabel("y")
plt.show()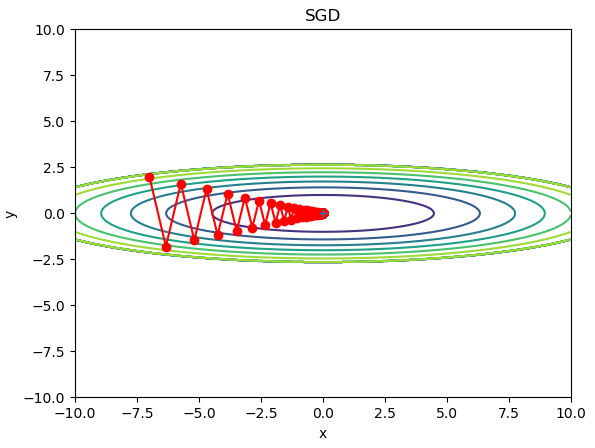
SGDの欠点
CGDは単純で実装も簡単ですが、上記グラフを見てわかるようにジグザグに動くので非効率と言われています。
SGDに代わる手法として、Momentum、AdaGrad、Adamという手法が一般的に使われているようです。
引用元
オライリーJapan 斎藤康毅 著 「セロから作るDeep Learning」