Pythonの配列とNumPyの配列の違い
Pythonには標準で配列を持っています。何故?NumPyにも配列が存在するのでしょうか?「車輪の再開発ではないか?」なんて言われそうですが・・・実はNumPyの配列を使うことの利点が沢山あります。
Pythonリストには1つのリスト内にさまざまなデータ型を含めることができますが、NumPy配列はすべての要素が同種である必要があります。配列の要素が均一であることで非常に効率的処理を行えます。
そのため、NumPy配列は非常に高速でメモリ使用率もPython配列より少なく済む。という利点があります。配列を使用する場合はNumPy配列を積極的に利用していきましょう。
配列を作成する方法
NumPy配列を作成するにはarray関数を使います。
単純な配列を作成するために必要なのはリスト要素を関数に引数に指定するだけで作れます。必要に応じてリスト内のデータの型を指定することもできます。
array関数
import numpy as np
a = np.array([1, 2, 3])
print(a)
配列を作る方法はarray関数だけではありません。他の方法もありますので紹介します。
すべての要素が0のリストを作る
zeros関数
np.zeros(2)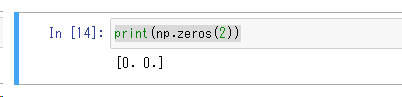
zeros関数を使うと、すべての要素が0の配列を作ることができます。配列の要素数はzeros関数の引数に指定した数で決まります。引数を指定しないと空の配列を返します。
すべての要素が1のリストを作る
ones関数
np.ones(2)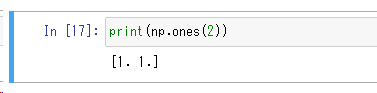
ones関数を使うと、すべての要素が1の配列を作ることができます。配列の要素数はones関数の引数に指定した数で決まります。引数を指定しないと空の配列を返します。
すべての要素がランダムのリストを作る
empty関数
np.empty(2)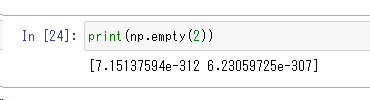
empty関数を使うと、ランダムな値で配列が作られます。上記で紹介したzeros関数やempty関数を使う理由は処理速度です。後からすべての要素を埋めることを前提に、とりあえず配列を作りたい場合に利用しましょう。
※後ですべての要素を埋めることを忘れずに行ってください。
様々な要素のリストを作る
arange関数
np.arange(4)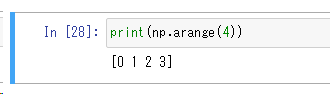
arange関数は引数に指定した数分、0から1ずつ増加しながら指定の要素を埋めた配列を作ることができます。 単純に連番で配列を作りたいときは便利です。
np.arange(2, 12, 2)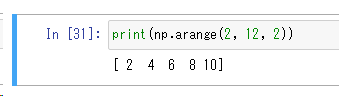
arange関数に最初の数値、最後の数値とステップサイズをカンマ(,)で区切って指定すると、最後の数値になるまでステップ数分ずつ増加した要素を持った配列を作ります。
linspace関数
np.linspace(0, 10, num=5)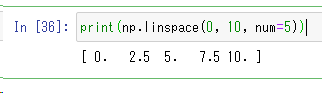
linspace関数は、指定した間隔で直線的に間隔を空けた値を持つ配列を作成することができます。右の例だと、0から10までの値を5分割した配列を作っています。”2.5”や”7.5”が等間隔になる値を自動計算された値が入ります。
配列の要素を小数点から整数にするには
「dtype」キーワード
np.linspace(2, 12, num=7, dtype=np.int64)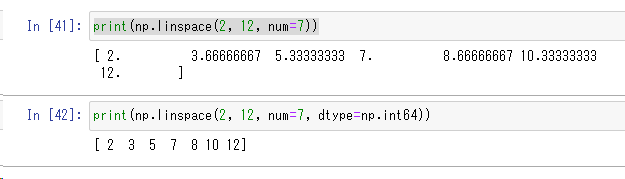
NumPyの配列(リスト)は、デフォルトのデータ型が浮動小数点(np.float64)です。これは「dtype」キーワードを使うことで他のデータ型して配列を作ることができます。左の例では、「int64」を指定して整数型で配列を作っています。
配列の要素を並び替える
sort関数
arr = np.array([2, 1, 5, 3, 7, 4, 6, 8])
print(np.sort(arr))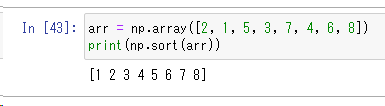
要素の並べ替えはsort関数で簡単に実現できます。関数を呼び出すときに、軸、種類、順序を指定することができます。
dtype = [('name', 'S10'), ('height', float), ('age', int)]
values = [('Takashi', 175.6, 41),('Masato', 168.8, 38),('Athushi', 172.7, 34)]
b = np.array(values, dtype=dtype)
np.sort(b, order='height')
orderキーワードを利用して構造化配列を並び替える例をご紹介します。左の例では、「名前、身長、年齢」という属性持った構造化された配列の中で”身長”を基準に昇順で並び替えます。
dtype = [('name', 'S10'), ('height', float), ('age', int)]
values = [('Masato', 168.8, 38),('Athushi', 172.7, 34),('Take', 167.8, 34)]
b = np.array(values, dtype=dtype)
np.sort(b, order=['age', 'height'])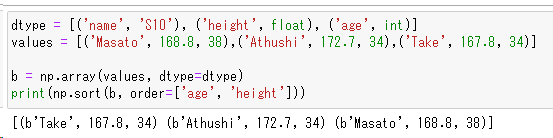
年齢で並べ替え、年齢が等しい場合は身長で並べ替えることもできます。
sort関数の定義
numpy.sort(a、axis = -1、kind = None、order = None)
配列のソートされたコピーを返します。
- パラメーター:
-
- array_like ソートする配列オブジェクト
- axis 整数値(int)、またはNone
-
並べ替える軸。Noneの場合は配列はソート前の状態を返します。デフォルトは-1で、最後の軸に沿ってソートされます。
- kind {‘quicksort’、 ‘mergesort’、 ‘heapsort’、 ‘stable’}
-
ソートアルゴリズム。デフォルトは「クイックソート」です。’stable’と ‘mergesort’はどちらも、内部でtimsortまたはradix sortを使用しています。’mergesort’オプションは、下位互換性のために残されているパラメータです。
- 戻り値:
-
- ソース済の配列:同じタイプ及び形状の配列を返します。
NumPy公式ドキュメント
配列の要素を追加する
concatenate関数
a1 = np.array([1, 2, 3, 4])
a2 = np.array([5, 6, 7, 8])
np.concatenate((a1, a2))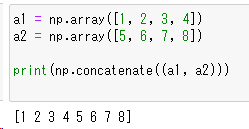
concatenate関数を使うと、配列同士を連結して1つの配列にすることができます。
x = np.array([[1, 2], [3, 4]])
y = np.array([[5, 6]])
np.concatenate((x, y), axis=0)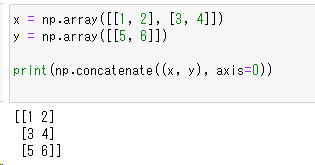
N次元配列化された配列でも連結させることができます。
concatenate関数の定義
numpy.concatenate((a1、a2、...)、axis = 0、out = None)
既存の軸に沿って配列のシーケンスを結合します。
- パラメーター:
-
- a1、a2、… array_likeのシーケンス
-
配列は、軸に対応する次元(デフォルトでは最初の次元)を除いて、同じ形状である必要があります。
- axis 整数(int)
-
アレイが結合される軸。axisがNoneの場合、配列は使用前にフラット化されます。デフォルトは0です。
- out 結合する別の配列
-
提供されている場合、結果を配置する宛先。形状は正しくなければならず、out引数が指定されていない場合に連結が返すものと一致している必要があります。
- 戻り値:
-
- 連結された配列。
NumPy公式ドキュメント
配列の形状や要素数を調べるには
NumPyの配列には、配列の形状や要素数を調べる関数が用意されています。配列のオブジェクト(array_example)を下記のように定義した前提で話を進めます。
array_example = np.array(
[
[
[0, 1, 2, 3],
[4, 5, 6, 7]
],
[
[0, 1, 2, 3],
[4, 5, 6, 7]
],
[
[0 ,1 ,2, 3],
[4, 5, 6, 7]
]
])ndim関数
array_example.ndim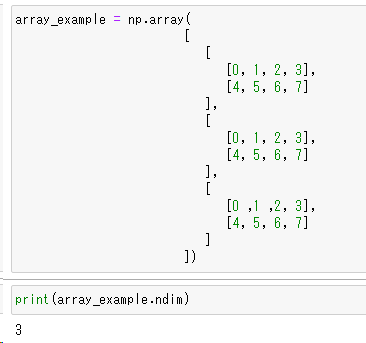
配列の軸の数または次元数を調べるためには、「配列オブジェクト.ndim関数」を使います。左図のarray_example配列オブジェクトは可読性を考慮してネストして表現しています。結果は3次元であることを返しています。
size関数
array_example.size
配列内の要素の総数を数えるには配列オブジェクト.size関数」を使います。要素の総数なので、次元数に関係なく値の個数を返します。
shape関数
array_example.shape
配列の形状を確認するには配列オブジェクト.shape関数」を使います。左図の通り要素数が(3個、2個、4個)3次元配列であることがわかります。
任意のインデックス範囲の要素を取り出すには
サンプルデータ
こちらの配列データをベースに様々な配列要素の取り方をご紹介します。配列要素を1つずつ取り出すより、ある程度フィルタリングしてから取り出す方がパフォーマンスが改善することがあります。そんなに難しいルールではありませんので覚えておくと便利だと思います。
d = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])任意の要素数未満の要素を取り出す
print(a[a < 5])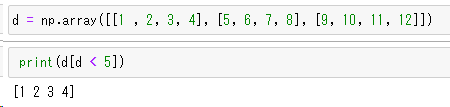
例えば、5未満の要素を取り出すには”d[d < 5]”という指定をすることでできます。結果は左図の通りです。
任意の値以上の値を持つ要素を取り出す
five_up = (d >= 5)
print(d[five_up])
右図は、値が5以上の要素を選択して取り出す例です。
偶数の値を持つ要素だけを取り出す
divisible_by_2 = d[d%2==0]
print(divisible_by_2)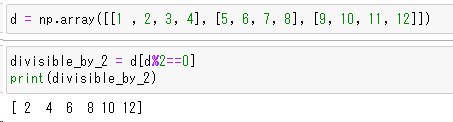
左図に2で割り切れる(偶数)要素だけを取り出す例をご紹介します。”d%2==0”という表現は「2で割った余りが0の場合」という条件を指定しています。当然ですが・・・”d%2==1”と指定すれば奇数の要素だけを取り出すことができます。
2つの条件を満たす要素を取り出す
e = d[(d > 2) & (d < 11)]
print(e)
&and| 演算子を使用して、次の2つの条件を満たす要素を取得することができます。左図の例では、3以上11未満の値を抽出しています。
配列の要素が条件を満たしているか調べるには
five_up = (d > 5) | (d == 5)
print(five_up)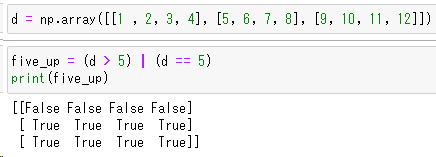
論理演算子&および|を利用し、配列内の値が特定の条件を満たすかどうかを指定するBool値を配列で返すことができます。
配列同士で四則演算を行う
サンプルデータ
サンプルデータは以下を使います。
data = np.array([1, 2])
ones = np.ones(2, dtype=int)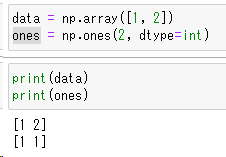
dataには[1,2]。onesには[1,1]という配列のデータが入っている状態で四則演算を行ってみましょう。
配列同士の足し算
print(data + ones)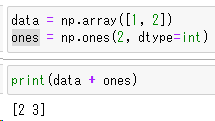
配列同士の計算とは思えないほど簡単に行えます。要素1と要素2同士で計算された結果が返ります。
配列同士の引き算
print(data - ones)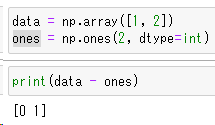
引き算も同じように行えます。[1,2]と[1,1]の引き算なので[0,1]と結果が出ます。
配列同士の掛け算
print(data * data)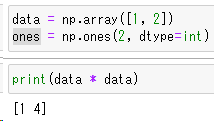
onesの要素がそれぞれ1で掛け算の結果が解りにくいので、data配列どうしで乗算を行っています[1,2]と[1,2]の掛け算なので[1,4]と結果が出ます。
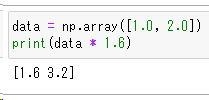
配列と整数の計算もできます。[1.0]と[2.0]それぞれに1.6を掛け算をしているの結果は [1.6]と[3.2]と結果がでます。
配列同士の割り算
print(data / data)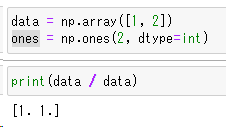
data配列どうしで除算を行っています[1,2]と[1,2]の割り算なので[1,1]と結果が出ます。
まとめ
NumPyの基本的な配列を作り方。使い方をご紹介しました。まだまだ沢山の機能がありますが、今回はここまでとします。また、新しい機能が追加されるとか、便利な機能を見つかりましたら、ご紹介したいと思います。
では、また。